- 논문 원문 : LLaMA-Mesh : Unifying 3D Mesh Generation with Language Models
- 프로젝트 페이지 : Nvidia Research : LLaMA-Mesh
Abstract
- 이 논문은 대규모 언어모델(LLM)의 능력을 확장시켜서, 하나의 통합된 모델 안에서 텍스트 입력으로 3D 메시를 생성(text-to-3D Mesh)하는 방법을 탐구한다.
- 이 연구는 다음과 같은 장점을 제공할 수 있다.
- (1) LLM 안에 임베딩된(=학습된) 공간적 지식(spatial knowledge)을 활용할 수 있게 된다.
- (2) 대화방식을 통한 3차원 (객체) 생성과 3차원 메시에 대한 이해를 가능하게 한다.
- 이 작업에서 가장 어려웠던 점은 3차원 메시 데이터를 LLM이 처리할 수 있는 개별 토큰이 되도록 효과적으로 토큰화(tokenization)하는 방법이었다.
- 이 문제의 해결을 위하여, 해당 논문에서는 LLaMA-Mesh를 제안한다.
- LLaMA-Mesh는 3D 메시의 정점(Vertext, 이하 vertext) 좌표와 삼각형 면(Face, 이하 face) 정의를 평문(plain text)으로 표현함으로써, LLM의 단어목록(vocabulary)을 확장하지 않고 LLM에 바로 통합시킬 수 있다.
- 또한, 사전훈련된(pretrained) LLM이 다음의 작업이 가능하도록 (추가학습할 수 있는) 데이터셋을 구성하였다.
- 참고) 질문-응답 쌍으로 구성되어 있어서, 정답이 있는 ( → 지도, Supervised) 데이터셋이며, 사전훈련된 모델을 해결하려는 태스크에 맞춰 파인 튜닝(→미세 조정, fine-tuning)을 위한 데이터셋이라는 의미에서, 보통 SFT(Supervised fine-tuning) 데이터셋이라고 얘기한다.
- (1) 텍스트 프롬프트로부터 바로 3D 메시를 생성할 수 있게 한다.
- (2) 필요할 경우, 텍스트와 3D 메시가 함께 결합된(interleaved) 결과를 출력할 수 있다.
- (3) 3D 메시를 이해하고 해석할 수 있다.
- 이 논문은 LLM이 텍스트 기반의 입력 포맷으로부터 3D 메시 생성을 위해 필요한 복잡한 공간 정보를 획득할 수 있도록 파인 튜닝함으로써, 3D 메시와 텍스트라는 방식(=모달리티, modalities)이 효과적으로 통합될 수 있음을 설명한 첫 시도이다.
- LLaMA-Mesh는 (LLM의) 강력한 텍스트 생성 능력을 유지하면서, (파인 튜닝 대신) 처음부터 학습된 모델들과 동등한 수준의 메시 생성 수준을 달성하였다.
1. Introduction
- 대규모 언어모델(LLM)은 인간이 사용하는 자연어를 이해하고 생성하는 뛰어난 능력을 보였고, 이를 바탕으로 대화용 에이전트, 코드 생성, 시각 정보 추론 등의 응용에서도 성공적으로 활용되고 있다.
- 하지만, 이러한 생성 능력이 주로 텍스트에 한정됨으로써, 다양한 태스크의 응용에는 한계가 있다는 의견도 제기된다.
- 이 논문은 LLM을 새로운 모달리티로 확장하는 시도를 한다.
- 3D 메시 생성(3D mesh generation)을 LLM으로 다룰 수 있다면 컴퓨터 그래픽스, 로보틱스와 같은 공학분야와 가상/증강 현실과 같은 분야에 새로운 가능성이 열릴 것이다.
- LLM이 글로 된 묘사로부터 3D 메시를 생성하게 한다는 것은 언어적 이해능력과 3차원 객체 생성을 통합함으로써, LLM의 활용 범위를 확장함을 의미한다.
- 또한 이런 방식은 3차원 콘텐츠 생성을 언어 기반의 지시로 가능하게 하는 직관적이고 효과적인 워크플로우를 제시할 수 있을 것이다.
- 그러나 새로운 입/출력 방식(모달리티)을 LLM으로 통합하는 것은 쉽지 않은 일이다.
- 특히, 새로운 모달리티를 처리하여 LLM에 입력하기 위한 토큰화 과정이 어렵다. (tokenization process for processing the new modality)
- 그동안 3차원 메시와 텍스트 생성을 단일한 프레임워크 안에서 통합하려는 시도는 없었다.
- 몇몇 연구들은 이미지와 텍스트 생성을 통합하기 위한 연구를 진행하였는데, 이 중 가장 일반적인 방식은 새로운 토크나이저를 학습시키는 방법이었다.
- 예) VQ-VAE (Vector-quantized Variational Auto-encoder) : 새로운 모달리티를 개별적인(discrete) 토큰으로 인코딩(=부호화)하여서 훈련 때 사용
- 그러나 이런 접근 방식은 단어 목록(vocabulary)을 확장시킬 필요가 있는데, 조정을 위한 학습 비용(adaptation's learning cost)의 증가를 의미하게 된다.
- 추가적으로 이 방법은 오토-인코딩 과정에서 정보 손실(information loss)이 발생할 수 있다.
- 이런 한계를 극복하기 위해, 이 논문은 LLaMA-Mesh를 제안한다.
- 3D 메시를 평문(plain text)로 표현함으로써, LLM이 3D 메시를 생성할 수 있게 해주는 새로운 프레임워크
- 3차원 모델을 표현하는 텍스트 기반의 표준으로서 널리 사용되는 OBJ 파일 형식을 사용하였다. obj 파일은 점의 좌표(vertext coordinates)와 면의 정의(face definition)로 구성된다.

- 수치 표현을 일련의 텍스트 표현으로 다룸으로써, LLaMA-Mesh는 3D 메시를 LLM이 직접 다룰 수 있는 형식으로 바꾼다.
- 이는 토크나이저나 단어집합의 수정의 필요성이 없기 때문에, 추가적인 훈련 오버헤드를 최소화할 수 있다.
- 이 논문은 또한 미세조정을 위한 SFT(supervised fine-tuning) 데이터셋을 구성하였다.
- 여기에는 (1) 텍스트-3D 메시 쌍과 (2) 텍스트와 3D메시가 결합(interleaved)된 대화가 포함되엇다.
- 추가 훈련에 사용한 사전훈련 모델은 LLaMA-3.1-8B-Instruct 이다.
- LLaMA-Mesh를 통해, 이 논문은 LLM이 텍스트 형식으로 변환된 3D메시의 수치정보를 학습함으로써, 복잡한 공간 정보를 얻을 수 있음을 보인다.
- 파인튜닝 수행 후에 LLaMA-Mesh는
- (1) 텍스트 프롬프트로부터 3D 메시를 생성할 수 있고,
- (2) 대화 환경에서 텍스트와 3D 메시가 결합되거나 번갈아가면서 니오는 결과를 출력할 수 있고,
- (3) 메시에 대하여 자연어로 서술 할 수 있다.
- LLaMA-Mesh는 LLM이 3차원 콘텐츠를 자연어로 생성하는 능력을 3D 메시와 텍스트가 통합된 단일 모델 안에서 가능하게 한 첫번째 성공 사례다.
- LLM이 가진 강력한 텍스트 생성 능력은 유지시키면서, 처음부터 학습된 3D 메시 생성 모델과 비견되는 성능을 달성하였다.
2. Related Work
2.1. Enabling LLMs to be Multi-Modal
- 대규모 언어모델(LLM)을 확장하여, (비전과 언어처럼) 여러 모달리티를 함께 처리하고 동시에 생성하는 통합모델에 관한 연구는 활발하게 이뤄지고 있다.
- 시각 정보 입력을 이해하여 여러 모달리티로써 상호작용하는 LLM 모델 연구
- 새로운 시각 토크나이저(visual tokenizer)를 사용하여, 이미지와 텍스트 생성의 통합 연구
- 이 논문은 이러한 연구방식과 달리, 토큰화 방식의 수정을 피하고 3차원 정보에 초점을 맞추기 위하여, 단순히 텍스트 형태의 OBJ 파일포맷으로 출력하는 방식을 사용한다.
- 이 논문과 매우 밀접한 연구로서 미리 정의된 객체들로 구성된 레이아웃을 생성하여서 3차원 장면을 LLM이 생성하게 하는 연구들이 있다.
- Holodek : Language Guided Generation of 3D Embodied AI environments
- The Scene Language : Representing Scenes with Programs, Words and Embeddings
- 그러나 이 연구들은 LLM이 3D 메시를 직접 생성할 수는 없다.
- LLaMA-Mesh는 LLM이 3차원 객체 생성 도구를 사용하게 하는 대신 텍스트로서 3D 메시를 직접 생성하는 첫번째 연구다.
2.2. 3D Object Generation
- 사전 훈련된 대규모(large-scale) 텍스트-투-이미지(text-to-image) 디퓨전 모델로부터 score-distillation을 사용해 3차원 객체를 생성한 연구들에 DreamFusion, Magic3D, ProlificDreamer 등이 있다.
- LRM, CRM, InstantMesh 등을 포함한 피드포워드(Feed-forward) 방식은 테스트 때의 최적화(test-time optimization) 없이 3차원 객체를 생성한다.
- 그러나 이러한 방식들은 일반적으로 3차원 객체를 수치값으로 다루고, 마칭 큐브(marching cube) 등을 사용해서 메시를 추출하기 때문에, 개별 토큰으로 분리하기 쉬운 표현으로 나타내기 어렵다.
2.3. Auto-Regressive Mesh Generation
- 반면에 PolyGen, MeshGPT, MeshXL 같은 방식은 3차원 객체를 토큰화된 좌표의 개별 시퀀스로 모델링하고, 자기 회귀 방식의 트랜스포머(auto-regressive transformer)를 사용하여 실제 사람이 만든것 같은 모양(=위상, topology)의 객체를 생성한다.
- MeshAnything, PivotMesh, EdgeRunner는 포인트 클라우드(point cloud)를 객체 생성을 조절하기 위한 입력 조건으로 받아 들인다.
- 이러한 연구들이 비록 auto-regressive transformers 모델이 생성한 개별토큰으로 메시를 다루지만, 이들은 데이터를 사용해 처음부터(from scratch) 학습시켰거나, 언어적인 능력(language capabilities)이 부족하다.
3. Method

3.1. 3D Representation
- LLM이 직접 3D 메시를 생성하도록 하려면, (3차원 메시라는) 새로운 모달리티를 LLM이 효과적으로 처리할 수 있도록 토큰화하는 것이 중요한 문제다.
- 사전훈련된 LLM은 obj 파일 포맷으로 3차원 객체를 생성할 수 있었다.
- obj 파일 포맷은 단순하면서도 널리 쓰이는 평문 형식의 객체 서술 방식이다.
- 이 때, (특별한 추가 적응 등이 필요하지 않는) 제로샷(zero-shot) 방식이 가능하였다.

- 비록 생성된 모양이 단순하고, 즉시 사용가능한 형태는 아니었지만(=렌더링이 필요하지만), obj 파일 포맷의 3차원 정보가 LLM 안에 내재되어 있음을 설명할 수 있다.
- 추가적으로, obj 파일이 평문 형태로 3차원 기하정보를 담고 있기 때문에, 토크나이저나 단어집합을 수정할 필요 없이 LLM과 통합하기에 이상적인 형식이라고 생각할 수 있다.
- obj 파일은 정점 좌표(vertex coordinates)와 면에 대한 정의(face definition)의 리스트로 구성된다.
- Verticies (v)
- 알파벳 v 로 시작하는 각 줄은 3차원 공간에서의 정점 좌표를 x, y, z 순으로 정의한다.
- 예) v 0.123 0.234 0.345
- Faces (f)
- 알파벳 f 로 시작하는 각 줄은 폴리곤(polygon)을 형성하는 정점의 인덱스를 나열하여, 면(face)을 정의한다.
- 3차원 그래픽스에서 폴리곤(polygon)은 삼각형(triangle) 또는 사각형(quadrilateral)의 형태다.
- 예) f 1 2 3
- Verticies (v)
- 이처럼 수치값을 (일반적인 문자열로 나타내어진) 평문(plain text)로 다룸으로써, 3D 메시를 LLM이 자연스럽게 다룰 수 있는 연속적인 텍스트 형태로 변환할 수 있다.
- 참고) 인터넷에 있는 obj 파일 포맷은 조금씩 다를 수 있기 때문에, 이 논문에서는 가장 널리 사용되며 직관적으로 이해되는 형태를 적용하였다고 한다.
- 3D 메시의 좌표는 일반적으로 부동 소수점(floating-point) 수치로써 저장된다.
- 그런데 부동소수점 수치를 각 정점의 좌표를 표현하는데 사용한다면,
- 토큰 시퀀스의 길이가 길어질 수 있고
- 대부분의 LLM의 컨텍스트(context) 길이 제한을 초과할 수 있으며
- 연산비용을 증가시키게 된다.
- 이 문제의 해결을 위하여, 정점의 좌표를 각 축마다 고정된 64개의 구간(bin)으로 (변환하는) 양자화를 시행하였다.
- 메시를 [0, 64]의 범위로 스케일링하고, 가장 가까운 정수값으로 좌표를 양자화한다.
- 다음은 이러한 양자화 과정에 대한 그림으로서, 약간씩 좌표의 정밀도(precision)가 감소하게 된다.
- 그러나 이 과정은 눈에 띌 정도로 토큰의 수를 줄여준다. 이 과정에서 기하학적인 정확도(geometric fidelity)를 희생하지 않으면서도 긴 시퀀스 또한 LLM이 다룰 수 있게 된다.

3.2. Pretrained Models
- LLaMA와 LLaMA 기반의 변형모델들과 같은 사전훈련된 LLM(pretrained LLM)은 다음의 이유에서 텍스트로부터 3D 메시 생성을 위한 도구로서 사용할 수 있다.
- (a) 임의의 시퀀스를 모델링하기에 강력한 도구이다.
- (b) 사전 훈련 과정에서 (3D 메시가 표현된 토큰 시퀀스와) 유사한 데이터를 학습했을 가능성이 있다.
- 이 논문에서는 LLaMA 3.1-8B-Instruct 모델을 베이스 모델로 사용하였다.
- LLaMA-3.1-8B Instruct 모델을 선택한 이유는 성능과 연산 효율성과의 균형이 뛰어난 모델이기 때문이다.
- 이 모델은 지시에 따르도록 (추가학습에 의해) 조정되어서(instrutction-tuned), 입력되는 프롬프트를 따르고 일관성있는(coherent) 응답을 생성할 수 있다.
- 이런 성격은 입력되는 텍스트 프롬프트를 해석하고 그에 따른 3D 메시를 생성하려는 LLaMA-Mesh응용에 유리할 수 있었다.
- 놀랍게도 파인튜닝 없이도 완벽하지는 않지만 간단한 형태의 OBJ 파일을 생성할 수 있었다.
- 이는 위의 Figure 6 과 같은 경우는 깃허브에서 접근가능한 예제들이기 때문이라고 생각한다.
- 그러나 이러한 강점에도 불구하고, 실제로는 파인튜닝이 없이는 메시 생성 작업에서 사전훈련된 LLaMA 모델의 성능은 좋지 않았다.
- 이처럼 (이 논문에서 사용하려는) 평문으로 된 메시 표현을 포함한 특수한 데이터셋에서는 모델을 파인튜닝하는 것이 필요함을 알 수 있다.
- 엄선된 텍스트-(대응되는)메시 쌍 데이터셋에서 LLaMA를 파인튜닝함으로써
- 모델은 OBJ파일의 패턴과 문법(semantics)을 학습할 수 있었고
- 이를 통해, 추가학습된 모델은 글로된 서술(textual description)로부터 유효한 3D 메시를 바로 생성하는 것이 가능해졌다.
3.3. 3D-task Finetuing
- LLM이 3D (메시)생성 능력을 갖추게 하려면, 우선 파인튜닝을 위한 정답 데이터셋(SFT 데이터셋)을 구성해야 한다.
- 이 논문에서는 일반적인 객체에 대한 통합적인 3D 데이터셋인 Objaverse로부터 3D 메시 데이터셋을 사용하였다.
- 이로부터 대화방식의 데이터셋(chat dataset)의 구성을 위해서
- (1) 규칙 기반의 접근방식(rule-based approach)과
- (2) LLM 기반의 데이터 증강(=확장)(LLM-based augmentation)을 사용하였다.
- 규칙 기반의 데이터셋 구성방식에서는
- 아래와 같이 단순한 형태의 몇몇 패턴을 설계하였다.
- 메시 이해를 위한 패턴 : "(user) {obj} What is this? (assistant) {caption}"
- 메시 생성을 위한 패턴 : "(user) Create a 3D model of {caption}. (assistant) {obj}"
- 각 3차원 객체에 대해서, 무작위로 어떤 패턴을 사용할지를 선택하고, {obj}나 {caption}과 같은 플레이스 홀더 부분을 메시에 대한 정의나 캡션으로 대체했다.
- 어쩌면 이런 대화방식이 직관적으로 보일만큼 간단해보이지만,
- 이렇게 구성된 데이터셋은 LLM에게 텍스트와 3차원 표현 사이의 대응에 관한 기본적인 지식을 제공해 줄 수 있었다.
- 더 복잡한 대화가 가능하도록, 복잡한 텍스트-3D 대화 데이터셋을 구성했다.
- 텍스트와 3차원 메시 정보가 번갈아가는 형태(interleaved format)로 샘플 대화를 구성하고, 문맥 학습(ICL, In-context learning)을 사용한 프롬프트를 통해
- 사전훈련된 LLM이 텍스트 서술에 기반하여 각 3차원 객체마다 대화를 생성하게 하였다.
- 규칙기반 방식과 LLM 데이터 증강 방식을 결합하여 사용하였다.

- 추가로 LLM의 언어적 능력을 보존하기 위하여, 일반적인 대화 데이터셋인 UltraChat을 사용하였다.
- 결과적으로 최종 데이터셋은 메시 이해, 메시 생성과 일반적인 대화 데이터로 구성되며, 구성 비율은 다음과 같다.

4. Experiments
4.1. Implementation Details
데이터셋 준비
- Objaverse 데이터셋 중에서 감당할 수 있는 수준의 연산 복잡도를 유지하기 위해, 면의 수가 최대 500개 이하인 메시들을 선택하였다.
- 이 결과 최종 3,100(31k)개의 메시가 데이터셋에 포함되었다.
- 선택된 메시 데이터들은 OBJ파일 형식으로 변환하였다.
- 앞서 설명된 것과 같이, 기하학적인 세부사항을 크게 희생하는 일 없이 토큰 시퀀스의 길이를 줄일 수 있도록, 각 정점의 좌표는 64개의 정수값(bins)으로 양자화 하였다.
- 각 메시에 필요한 캡션은 Cap3D으로 생성하였다.
- 과적합을 피하기 위해서, 각 메시를 { 0º, 90º , 180º , 270º } 중 하나로 회전시켰고, 최종적으로 12,5000(125k)개의 메시가 되었다.
- 이전 연구에 해당하는 PivotMesh에 마찬가지로, 정점은 z-y-x 순의 좌표를 오름차순으로 정리하였다.
- 각 면의 인덱스도 오름차순으로 정리하였다.
- LLM의 컨텍스트 길이제한은 8k 토큰으로 설정하였다.
모델 훈련
- 모델은 32개의 A100 GPU에서 21,000(21k) 에포크(iteration)만큼 훈련되었다.
- (lora를 사용하지 않고) 전체 파라미터에 대한 파인튜닝(full parameter finetuing)을 수행하였다.
- 옵티마이저는 AdamW를 사용하였고, 이 때 학습률은 1e-5 이며, 최초 30 스텝의 웜업(warm-up) 단계 이후에는 코사인 스케줄링(cosine scheduling)으로 학습하였다. 배치 크기는 128이었다.
- 이러한 설정 하에서 총 학습시간은 대략 3일 정도였다.
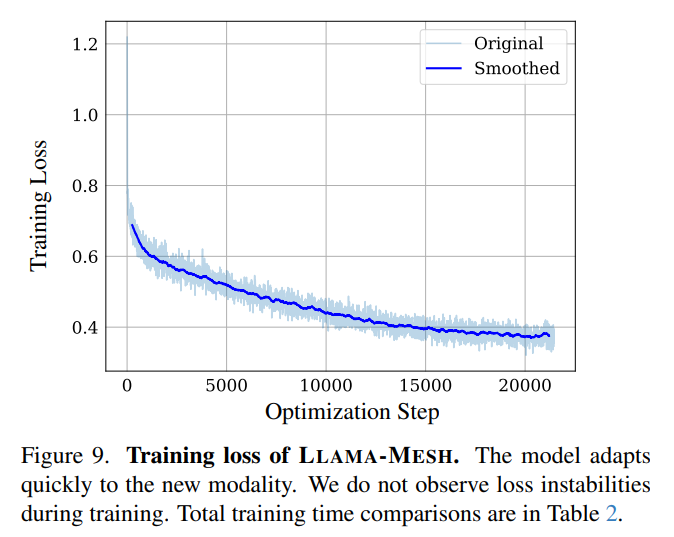
- 아래의 손실함수 변화에 관한 학습 그래프를 보게되면, 새로운 입력 방식(모달리티)에 대해서 모델이 빠르게 수렴함을 알 수 있다.
- 이는 모델이 새로운 지식에 대해 빠르게 적응(adaptation)함을 의미한다.
- 한편, 훈련 과정에서 손실함수가 갑자기 크게 변화하거나(loss spiking) 불안정한 학습 상황은 관찰되지 않았다.
4.2. Results
4.2.1. Mesh Generation Results

- 위의 그림은 LLaMA-Mesh에 의해 생성된 고품질 메시들이다.
- 이전의 자기-회귀(auto-regressive) 메시 생성 방법의 결과와 비슷하게, LLaMA-Mesh는 사람이 직접 만든것과 같은 모양(artist-like topology)을 생성할 수 있었다.
- 이는 LLaMA-Mesh가 훈련 동안 메시의 모양(=위상, topology)을 학습했기 때문이다.
- 생성된 메시의 다양성을 평가하기 위해서, 동일한 텍스트 프롬프트를 여러번 입력하고, 출력되는 결과 메시의 변화를 관찰하였다.
- 다음 그림은 모델이 프롬프트를 만족하여 고유한 메시를 생성할 때 다양성을 보일 수있음을 보여준다.
- 이는 LLaMA-Mesh가 다양하면서도 창의적인 결과를 출력할 수 있는 능력이 있음을 강조한다.
- 또한 이런 다양성은 다양한 디자인 옵션과 변화를 필요로 하는 응용에 필수적이다.

4.2.2. Language and Conversational Abilities
정성적 결과
- 메시 생성을 위한 파인튜닝 후에, LLaMA-Mesh가 언어를 이해하는 능력을 여전히 가졌는지 여부를 평가하였다.
- 아래 그림과 같이 LLaMA-Mesh는 일관성있고 문맥적으로 적절한 대화에 참여하여 응답할 수 있으며, 복잡한 지시사항을 이해할 수 있었고, 명확한 질문을 하며 상세한 응답을 내놓았다.
- 이처럼 파인튜닝 후에도 LLM의 언어적 유창함은 그대로 유지되었다고 볼 수 있었다.

정량적 결과
- 아래의 표는 언어 능력을 정량적으로 평가한 결과다.
- LLaMA-Mesh의 성능을 다양한 크기의 베이스 모델의 성능과 비교하였다.
- LLaMA 3.1(8B), LLaMA 3.2(3B), LLaMA 3.2(1B)

- 사용된 평가 메트릭은 MMLU(5-shot), PIQA(0-shot), HellaSwag(0-shot), GSM8K(8-shot) 등이다.
- 이들은 언어모델의 일반적 지식, 상식 추론, 수학적인 문제 풀이 능력 등을 평가하기 위해 구성되어 있다.
- LLaMA-Mesh는 3D 메시 생성을 위해서 OBJ 파일을 만들도록 파인튜닝 되었지만, 베이스라인 모델들과 비교될 만큼의 언어적 이해능력과 추론 능력을 가지고 있다.
- 이러한 결과들은 LLaMA-Mesh가 LLM의 기능을 3차원 콘텐츠 생성으로 확장하면서도 여전히 원래의 언어적 능력을 보존할 수 있음을 보여준다고 볼 수 있다.
4.3. Comparison with Existing Methods
정성적 비교
- 3차원 생성 능력을 평가하기 위해서, 3D 메시 생성 분야의 최신 성능 모델과 비교하였다.

- 위의 비교 그림으로부터 LLaMA-Mesh가 동일한 텍스트 프롬프트가 주어졌을 때, 기존의 3D 생성모델과 비교할만한 성능의 메시를 만들어냄을 알 수 있다. 특히 상세한 세부사항을 반영하고, 복잡한 기하학 형태를 효과적으로 반영하였다.
- Unique3D와 MeshXL이 메시 생성을 위한 목적만을 위해 학습된 모델인 반면, LLaMA-Mesh는 언어 이해 능력을 일관성 있게 유지하면서도 동일한 성능을 단일 모델 안에서 달성할 수 있었다.
훈련 효율성 및 모델 크기
- 아래의 표는 여러 모델 간에 훈련 시간, 요구되는 연산자원, 모델 크기를 비교하였다.

- MeshXL은 메시 데이터에 대하여 거대한 트랜스포머(transformer) 모델을 훈련시켰기 때문에 상당한 연산 자원이 필요로 했다.
- 이에 비해, 사전훈련된 LLM을 활용하여 파인튜닝을 진행하는 경우, 훈련에 필요한 비용을 효과적으로 감소시킬 수 있었다.
5. Discussion
5.1. Limitations
- LLaMA-Mesh가 3D 메시를 생성할 수 있다는 LLM의 잠재력을 보여줬지만, 지속해서 해결해나가야할 몇 가지 한계점이 있다.
- 한정된 수의 정수값(bins)으로 정점의 좌표를 양자화할 때, 기하학적인 세부사항에서 손실이 생길 수 있다. 이로 인해 생성된 메시의 정확성(fidelity)에 영향을 미칠 수 있다.
- LLM의 컨텍스트 길이의 제한은 매우 복잡하거나 큰 규모의 3차원 구조를 생성하는 능력을 제한할 수 있다.
- 이 논문에서는 이를 고려하여 메시의 상세함 단계를 줄여서 최대 500개의 면을 가진 메시들까지만 생성하였다.
- (LLaMA-Mesh의 언어능력이 크게는 유지되지만) 파인튜닝 후에 언어적 능력 측면에서 약간의 성능저하가 일어났다.
- 이에 대해 이 논문의 추측으로는 텍스트 지시 데이터셋으로 오직 UltraChat에만 의존했기 때문으로 생각한다.
- 따라서 다양하며, 고품질 텍스트 지식 데이터셋을 통합해 사용한다면 LLaMA-Mesh의 언어 능력을 유지할 수 있을 것으로 생각된다.
- 3D 메시 훈련 데이터에 있어서도 Objaverse의 3D 데이터셋만 사용했기 때문에, 더 많은 데이터셋을 사용한다면 생성 결과를 더 풍부하게 만들 수 있을 것이다.
- 더불어 이 논문에서는 연산 자원상의 한계를 고려하여 8B모델만을 사용했지만, 더 많은 매개변수를 사용하는 큰 모델을 쓴다면 성능 향상을 기대할 수 있을 것이다.



댓글